Cette page décrit comment configurer les options avancées de la file d’attente Launch, y compris les modèles de configuration de file d’attente, les macros dynamiques et les images de base pour accélérateurs. Ces options aident les administrateurs à appliquer des garde-fous et à adapter les files d’attente à des environnements de calcul spécifiques.Documentation Index
Fetch the complete documentation index at: https://wb-21fd5541-update-reference-docs-34.mintlify.app/llms.txt
Use this file to discover all available pages before exploring further.
Configurer les modèles de configuration de file d’attente
Configurer un modèle de file d’attente
- Accédez à W&B Launch App.
- Sélectionnez View queue à côté du nom de la file d’attente à laquelle vous souhaitez ajouter un modèle.
- Sélectionnez l’onglet Config. Il affiche des informations sur votre file d’attente, comme la date de création de la file d’attente, sa configuration et les redéfinitions existantes au moment du lancement.
- Accédez à la section Queue config.
- Identifiez les paires clé-valeur de configuration pour lesquelles vous souhaitez créer un modèle.
- Remplacez la valeur dans la configuration par un champ de modèle. Les champs de modèle prennent la forme
{{variable-name}}. - Cliquez sur le bouton Parse configuration. Lorsque vous analysez votre configuration, W&B crée automatiquement des vignettes sous la configuration de la file d’attente pour chaque modèle créé.
- Pour chaque vignette générée, vous devez d’abord spécifier le type de données (
string, integer ou float) autorisé par la configuration de la file d’attente. Pour ce faire, sélectionnez le type de données dans le menu déroulant Type. - Selon le type de données, renseignez les champs qui apparaissent dans chaque vignette.
- Cliquez sur Save config.
launch config
InstanceType, votre configuration se présente ainsi :
launch config
aws-instance apparaît sous Queue config.
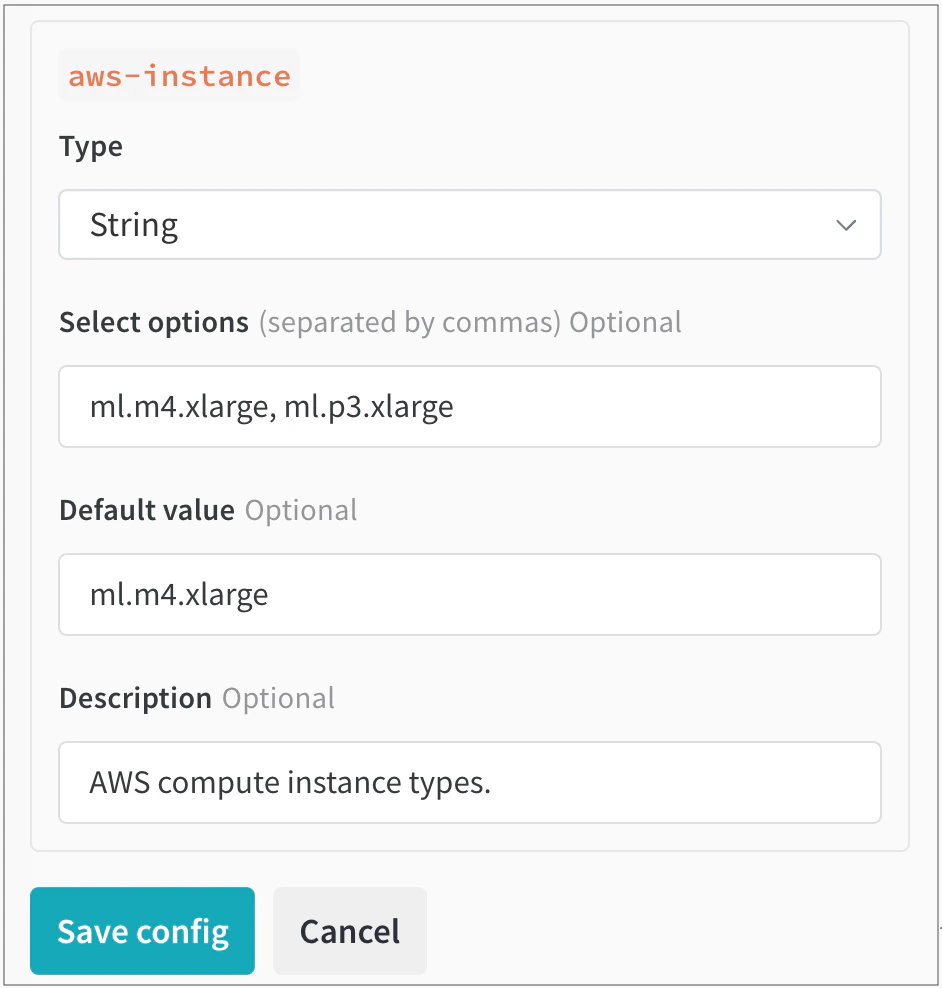
Vous sélectionnez ensuite String comme type de données dans la liste déroulante Type. Cela renseigne des champs dans lesquels vous pouvez indiquer les valeurs qu’un utilisateur peut choisir. Par exemple, dans l’image suivante, l’administrateur de l’équipe a configuré deux types d’instances AWS parmi lesquels les Users peuvent choisir, ml.m4.xlarge et ml.p3.xlarge :
Configurer dynamiquement les jobs Launch
| Macro | Description |
|---|---|
${project_name} | Le nom du projet dans lequel le run est lancé. |
${entity_name} | Le propriétaire du projet dans lequel le run est lancé. |
${run_id} | L’ID du run lancé. |
${run_name} | Le nom du run lancé. |
${image_uri} | L’URI de l’image de conteneur de ce run. |
Toute macro personnalisée ne figurant pas dans le tableau ci-dessus, par exemple
${MY_ENV_VAR}, est remplacée par une variable d’environnement issue de l’environnement de l’agent.Utilisez l’agent Launch pour créer des images qui s’exécutent sur des accélérateurs ou des GPU
- Compatibilité avec Debian. Le Dockerfile de Launch utilise
apt-getpour récupérerpython. - Jeux d’instructions matériels CPU et GPU compatibles. Assurez-vous que votre version de CUDA est prise en charge par le GPU que vous prévoyez d’utiliser.
- Compatibilité entre la version d’accélérateur que vous fournissez et les packages installés dans votre algorithme de ML.
- Toute étape supplémentaire requise pour configurer les packages installés afin d’assurer leur compatibilité avec le matériel.
Utiliser des GPU avec TensorFlow
builder.accelerator.base_image dans la configuration des ressources de la file d’attente.
Par exemple, l’image de base tensorflow/tensorflow:latest-gpu garantit que TensorFlow utilise votre GPU. Vous pouvez la configurer dans la configuration des ressources de la file d’attente.
L’extrait JSON suivant montre comment spécifier l’image de base TensorFlow dans la configuration de votre file d’attente :
Queue config